


New! Render PlantUML diagrams directly inside GitHub
with our official browser extension —
No server. No tokens. No tracking. Zero permissions but clipboard. —
Try it out and let us know what you think!
Visualiser les Regex avec PlantUML
Introduction aux Regex et aux défis de la visualisation
Les expressions régulières (Regex) sont des outils puissants en programmation, utilisés pour la recherche de motifs et la manipulation de texte. Bien qu'extrêmement utiles, les motifs Regex peuvent souvent être denses et difficiles à interpréter, en particulier lorsqu'ils deviennent de plus en plus complexes. La syntaxe, bien qu'efficace, peut devenir obscure et difficile à lire pour les débutants comme pour les développeurs expérimentés. C'est là que des outils visuels comme PlantUML entrent en jeu.Pourquoi PlantUML pour Regex ?
Simplifier la complexité grâce à la visualisation
PlantUML, un outil populaire pour créer des diagrammes UML, offre une fonctionnalité unique pour ceux qui sont aux prises avec les complexités de regex. En transformant les modèles de regex en diagrammes visuels, PlantUML aide à :- Démystifier la syntaxe des regex : La représentation visuelle décompose la regex en composants compréhensibles, ce qui facilite la compréhension de chaque partie de l'expression.
- Améliorer la reconnaissance des formes : Les diagrammes visuels permettent aux utilisateurs d'identifier les schémas et structures répétitifs dans les regex, qui pourraient être manqués dans la forme textuelle.
- Débogage et optimisation : En présentant visuellement la structure des regex, PlantUML peut aider à repérer les redondances et les erreurs, facilitant ainsi la conception de modèles plus efficaces.
Un outil inestimable pour l'apprentissage et la collaboration
- Pour les apprenants, les diagrammes visuels servent d'aides pédagogiques, simplifiant la courbe d'apprentissage associée à la syntaxe des regex.
- Dans les environnements collaboratifs, les représentations visuelles peuvent combler le fossé de la compréhension, en s'assurant que les membres de l'équipe sont sur la même longueur d'onde en ce qui concerne la logique et la fonction d'un motif regex.
 Bases des expressions régulières
Bases des expressions régulières
Texte literal : PlantUML peut représenter les simples expressions littérales des expression régulières tel que montré avec l'exemple abc.

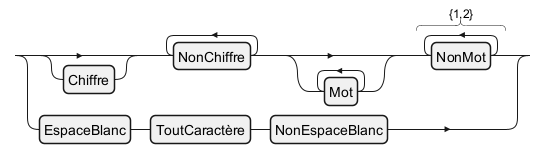
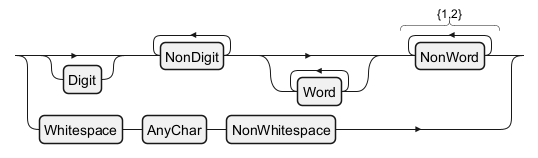
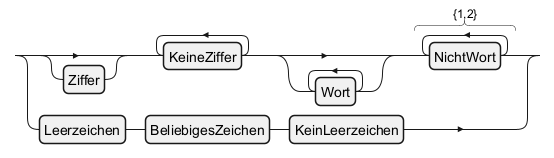
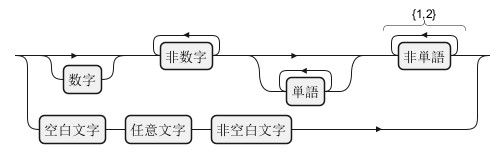
Character Classes and Sequences
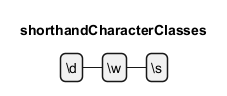
Shorthand Character Classes
In regular expressions, shorthand character classes offer a concise way to match common character types. The class\d matches any digit, \w matches any word character (including letters, digits, and underscores), and \s matches any whitespace character (including spaces, tabs, and line breaks).
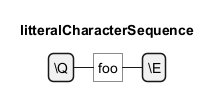
Literal Character Sequences
To ensure that a specific sequence of characters is interpreted exactly as written, without any special meaning, the\Q...\E escape sequence is used. For example, \Qfoo\E treats "foo" as a literal string, not as separate characters with potential special meanings in regex.
Character Ranges
Character ranges are a flexible way to specify a set of characters to match. For instance,[0-9] represents any digit from 0 to 9. This is particularly useful for matching characters within a specific range, like letters or numbers.

Any Character
The dot. in regular expressions is a powerful tool that matches any character except for newline characters. It's often used when the specific character is not important, or when matching a wide range of characters.
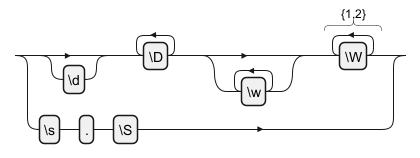
Special Escapes
Special escape sequences in regular expressions provide a way to include non-printable and hard-to-type characters in patterns. For example,\t represents a tab, \r a carriage return, and +++<br>+++ a newline. These escapes are essential for patterns that involve whitespace or other non-visible characters.

Descriptive Name and Language
Vous pouvez activer les descriptions avec !option useDescriptiveNames true.
Vous pouvez également choisir la langue de description avec l'option !option language <xx> dans laquelle <xx> est le code langue selon la Liste des codes ISO 639-1 .
Sans descriptions (par défaut)
Avec descriptions
Français (fr)
English (en)
Deutsch (de)
Japanese (ja)
Caractères d'échappement spéciaux
Caractères d'échappement Octal et Unicode
Les expressions régulières peuvent également inclure des caractères d'échappement en octal et Unicode pour représenter des caractères spéciaux. Code PlantUML pour caractères d'échappement en octal :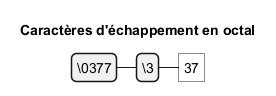

Repetitions and Alternation
Repetitions
Regular expressions provide versatile options for specifying how many times a particular pattern should occur. These repetition constructs make it possible to match varying lengths of text and are fundamental to the flexibility of regex.Optional Repetition
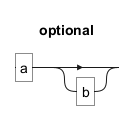
The? symbol indicates that the preceding element is optional, meaning it may appear zero or one time. For example, ab? matches either "a" or "ab".
Required Repetition
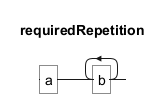
The+ symbol requires the preceding element to appear one or more times. In the pattern ab+, "b" must occur at least once following "a".
Zero or More Repetitions
The "*" symbol allows the preceding element to appear zero or more times. For instance, "ab*" matches "a", "ab", "abb", "abbb", and so on.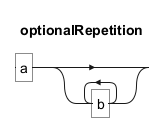
Specified Range of Repetitions
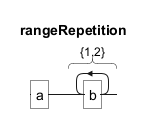
Curly braces{} are used to specify an exact number or range of repetitions. For example, ab{1,2} matches "ab" or "abb".
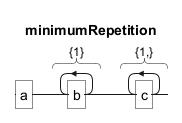
Minimum Number of Repetitions
To indicate a minimum number of repetitions, use the format{n,}. In ab{1}c{1,}, "a" is followed by at least one "b" and one or more "c".
Repetition Equivalence
Repetition constructs can often be expressed in multiple ways. For instance,a{0,1}b{1,} is equivalent to a?b+, both representing "a" as optional and "b" as required one or more times.

Alternation
Alternation, represented by the| symbol, allows choosing between multiple sequences, as in the example a|b, where either "a" or "b" is accepted.

Unicode
Unicode Categories
Unicode character categories in regular expressions allow for the matching of specific types of characters, such as letters or numbers, across various languages and scripts. PlantUML can visualize these categories, making it easier to understand their coverage.- Letters (
\p{L}): Matches any letter from any language. - Lowercase Letters (
\p{Ll}): Specifically matches lowercase letters.

Unicode Scripts
Unicode scripts are used to match characters from specific writing systems. For example,\p{Latin} matches any character from the Latin script, commonly used in Western languages.

Unicode Blocks
Unicode blocks refer to specific ranges of characters as defined in the Unicode standard. For instance,\p{InGeometric_Shapes} matches characters that are part of the Geometric Shapes block.
