


New! Render PlantUML diagrams directly inside GitHub
with our official browser extension —
No server. No tokens. No tracking. Zero permissions but clipboard. —
Try it out and let us know what you think!
Visualisierung von Regex mit PlantUML
Einführung in Regex und Visualisierungsherausforderungen
Reguläre Ausdrücke (Regex) sind mächtige Werkzeuge in der Programmierung, die für den Musterabgleich und die Textmanipulation verwendet werden. Obwohl sie äußerst nützlich sind, können Regex-Muster oft sehr dicht und schwer zu interpretieren sein, insbesondere wenn sie komplexer werden. Die Syntax ist zwar effizient, kann aber sowohl für Anfänger als auch für erfahrene Entwickler unübersichtlich und schwer zu lesen sein. Hier kommen visuelle Werkzeuge wie PlantUML ins Spiel.Warum PlantUML für Regex?
Vereinfachung der Komplexität durch Visualisierung
PlantUML, ein beliebtes Werkzeug zur Erstellung von UML-Diagrammen, bietet eine einzigartige Funktion für diejenigen, die sich mit den Feinheiten von Regex auseinandersetzen. Indem PlantUML Regex-Muster in visuelle Diagramme umwandelt, hilft es:- Regex-Syntax entmystifizieren: Die visuelle Darstellung zerlegt die Regex in verständliche Komponenten, was es einfacher macht, jeden Teil des Ausdrucks zu verstehen.
- Verbessert die Erkennung von Mustern: Visuelle Diagramme ermöglichen es Benutzern, sich wiederholende Muster und Strukturen in Regex zu erkennen, die in der Textform möglicherweise übersehen werden.
- Debugging und Optimierung: Durch die visuelle Darstellung der Regex-Struktur kann PlantUML bei der Erkennung von Redundanzen und Fehlern helfen und so einen effizienteren Entwurf von Mustern ermöglichen.
Ein unschätzbares Werkzeug für das Lernen und die Zusammenarbeit
- Für Lernende dienen visuelle Diagramme als Lehrmittel, die die Lernkurve im Zusammenhang mit der Regex-Syntax vereinfachen.
- In kollaborativen Umgebungen können visuelle Darstellungen die Verständnislücke überbrücken und sicherstellen, dass die Teammitglieder hinsichtlich der Logik und Funktion eines Regex-Musters auf derselben Seite stehen.
 Grundlagen der regulären Ausdrücke
Grundlagen der regulären Ausdrücke
Literaler Text: PlantUML kann einfache literale Texte in regulären Ausdrücken visualisieren, wie das Beispiel abc zeigt.

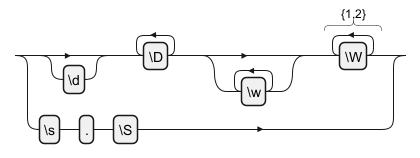
Zeichenklassen und -sequenzen
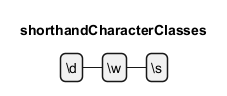
Kurzschrift-Zeichenklassen
In regulären Ausdrücken bieten Kurzschrift-Zeichenklassen eine prägnante Möglichkeit, gängige Zeichentypen zu finden. Die Klasse\d entspricht jeder Ziffer, \w entspricht jedem Wortzeichen (einschließlich Buchstaben, Ziffern und Unterstrichen) und \s entspricht jedem Leerzeichen (einschließlich Leerzeichen, Tabulatoren und Zeilenumbrüchen).
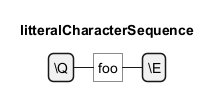
Wörtliche Zeichenfolgen
Um sicherzustellen, dass eine bestimmte Zeichenfolge genau so interpretiert wird, wie sie geschrieben wurde, ohne eine besondere Bedeutung zu haben, wird die Escape-Sequenz\Q...\E verwendet. Zum Beispiel behandelt \Qfoo\E "foo" als literale Zeichenkette und nicht als getrennte Zeichen mit möglichen Sonderbedeutungen in regex.
Zeichenbereiche
Zeichenbereiche sind eine flexible Möglichkeit, eine Gruppe von Zeichen für die Übereinstimmung anzugeben. Zum Beispiel steht[0-9] für jede Ziffer von 0 bis 9. Dies ist besonders nützlich für den Abgleich von Zeichen innerhalb eines bestimmten Bereichs, wie Buchstaben oder Zahlen.

Beliebiges Zeichen
Der Punkt. in regulären Ausdrücken ist ein leistungsfähiges Werkzeug, das auf jedes beliebige Zeichen mit Ausnahme von Zeilenumbrüchen passt. Er wird häufig verwendet, wenn das spezifische Zeichen nicht wichtig ist oder wenn ein großer Bereich von Zeichen abgeglichen werden soll.
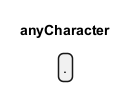
Spezielle Escape-Sequenzen
Spezielle Escape-Sequenzen in regulären Ausdrücken bieten eine Möglichkeit, nicht druckbare und schwer zu tippende Zeichen in Muster aufzunehmen. Zum Beispiel steht\t für einen Tabulator, \r für einen Wagenrücklauf und \\ einen Zeilenumbruch. Diese Escape-Sequenzen sind wichtig für Muster, die Leerzeichen oder andere nicht sichtbare Zeichen enthalten.

Descriptive Name and Language
You can activate the Descriptive Names with !option useDescriptiveNames true.
Then you can also choose the language of the Descriptive Names, with the !option language <xx> option where <xx> is the ISO 639 code of the language.
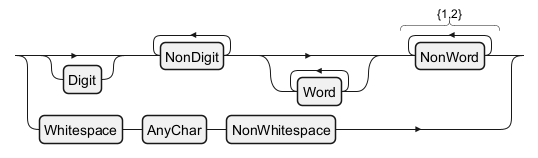
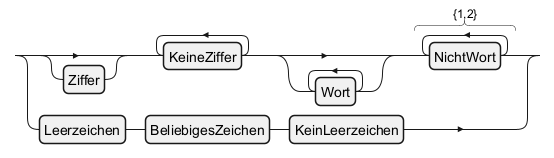
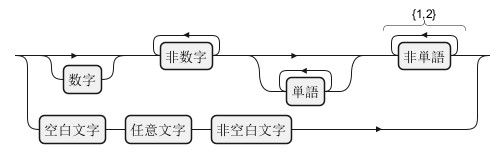
Without Descriptive Name (by default)
With Descriptive Name
English (en)
Deutsch (de)
Japanese (ja)
Spezielle Escapezeichen
Oktal- und Unicode-Escapes
Reguläre Ausdrücke können auch Oktal- und Unicode-Escapes enthalten, um bestimmte Zeichen darzustellen. PlantUML Code für Oktal-Escapes: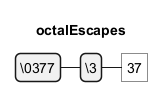

Wiederholungen und Abwechslung
Wiederholungen
Reguläre Ausdrücke bieten vielseitige Optionen, um festzulegen, wie oft ein bestimmtes Muster vorkommen soll. Diese Wiederholungskonstrukte ermöglichen es, unterschiedlich lange Texte abzugleichen und sind grundlegend für die Flexibilität von regex.Optionale Wiederholung
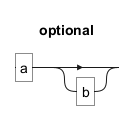
Das Symbol? zeigt an, dass das vorangehende Element optional ist, d.h. es kann null oder einmal vorkommen. Zum Beispiel passt ab? entweder auf "a" oder "ab".
Erforderliche Wiederholung
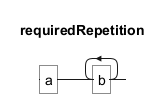
Das Symbol+ bedeutet, dass das vorangehende Element ein oder mehrere Male vorkommen muss. In dem Muster ab+ muss "b" mindestens einmal nach "a" vorkommen.
Null oder mehr Wiederholungen
Das "*"-Symbol erlaubt, dass das vorangehende Element null oder mehr Mal vorkommt. Zum Beispiel passt "ab*" zu "a", "ab", "abb", "abbb" und so weiter.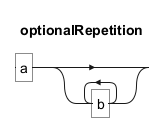
Spezifizierter Bereich von Wiederholungen
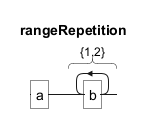
Geschweifte Klammern{} werden verwendet, um eine genaue Anzahl oder einen Bereich von Wiederholungen anzugeben. Zum Beispiel entspricht ab{1,2} "ab" oder "abb".
Mindestanzahl von Wiederholungen
Um eine Mindestanzahl von Wiederholungen anzugeben, verwenden Sie das Format{n,}. In ab{1}c{1,} wird "a" von mindestens einem "b" und einem oder mehreren "c" gefolgt.
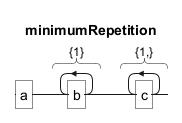
Äquivalenz von Wiederholungen
Wiederholungskonstrukte können oft auf mehrere Arten ausgedrückt werden. Zum Beispiel ista{0,1}b{1,} äquivalent zu a?b+, beide stellen "a" als optional und "b" als erforderlich ein oder mehrere Male dar.

Alternation
Alternation, dargestellt durch das Symbol|, ermöglicht die Wahl zwischen mehreren Sequenzen, wie im Beispiel a|b, wo entweder "a" oder "b" akzeptiert wird.

Unicode
Unicode-Kategorien
Unicode-Zeichenkategorien in regulären Ausdrücken ermöglichen den Abgleich bestimmter Zeichentypen, wie z.B. Buchstaben oder Zahlen, in verschiedenen Sprachen und Schriften. PlantUML kann diese Kategorien visualisieren, was es einfacher macht, ihre Abdeckung zu verstehen.- Letters (
\p{L}): Passt zu jedem Buchstaben in jeder Sprache. - Kleinbuchstaben (
\p{Ll}): Passt speziell auf Kleinbuchstaben.

Unicode-Schriften
Unicode-Schriften werden verwendet, um Zeichen aus bestimmten Schriftsystemen zu finden. Zum Beispiel passt\p{Latin} auf alle Zeichen der lateinischen Schrift, die in westlichen Sprachen häufig verwendet wird.

Unicode-Blöcke
Unicode-Blöcke beziehen sich auf bestimmte Zeichenbereiche, die im Unicode-Standard definiert sind. Zum Beispiel passt\p{InGeometric_Shapes} auf Zeichen, die Teil des Blocks Geometrische Formen sind.
